
Contents
🦀🦀🦀
Introduction
Hexagonal Architecture. You've heard the buzzwords. You've wondered, "why hexagons?". You think domain-driven design is involved, somehow. Your company probably says they're using it, but you suspect they're doing it wrong.
Let me clear things up for you.
By the end of this guide, you'll have everything you need to write ironclad Rust applications using hexagonal architecture.
I will get you writing the most maintainable Rust of your life. Your production errors will fall. Test coverage with skyrocket. Scaling will get less painful.
If you haven't read The Ultimate Guide to Rust Newtypes yet, I recommend doing so first – type-driven design is the cherry to hexagonal architecture's sundae, and you'll see many examples of newtypes in this tutorial.
Now, this is a big topic. Huge (O'Reilly, hit me up). I'm going to publish it section by section, releasing the next only once you've had a chance to digest the last and tackle the exercises for each new concept. Bookmark this page if you don't want to miss anything – I'll add every new section here.
I'll be using a blogging engine with an axum web server as our primary example throughout this guide. Over time, we'll build it into an application of substantial complexity.
The type of app and the crates it uses are ultimately irrelevant, though. The principles of hexagonal architecture are not confined to web apps – any application that receives external input or makes requests to the outside world can benefit.
Here's how to code it.
🦀🦀🦀
Part I
Anatomy of a bad Rust application
What problems does hexagonal architecture solve?
The answer to the question "why hexagons?" is boring, so we're not going to start there.
How To Code It is all about code! I'm going to start by showing you how not to write applications in Rust. By studying a Very Bad Application, you'll see the problems that hexagonal architecture solves clearly.
The Very Bad Application is the most common way to write production services. Your company will have code that looks just like it. Zero To Production In Rust writes its tutorial app in a similar way. In fairness, it has its hands full with teaching us Rust, and it only promised to get us to production, not keep us there.
The Very Bad Application is a scaling and maintainability time bomb. It is a misery to test and refactor. It will increase your staff turnover and lower your annual bonus.
Here's my take on main.rs for such a program:
rustsrc/bin/server/main.rs
This code loads the application config from the environment, configures some
tracing middleware, creates an Sqlite connection pool, and injects it into an
axum HTTP router. We have one route: POST /authors, for creating blog post
authors. Finally, it binds Tokio TcpListener to the application port and fires
up the server.
We're concerned about architecture, so I've omitted details like a panic recovery layer, the finer points of tracing, graceful shutdown, and most of the routes a full app would have.
Even so, this is fat main function. If you're tempted to say that it could be
improved by moving the application setup logic to a dedicated setup module,
you're not wrong – but your priorities are. There is much greater evil here.
Firstly, why is main configuring HTTP middleware 1? In fact, it looks like
main needs an intimate understanding of the whole axum crate just to get the
server running 4! axum isn't even part of our application – it's a
third-party dependency that has escaped containment.
You'd have the same problem if this code lived in a setup module. It's not the
location of the setup, but the failure to encapsulate and abstract dependencies
that makes this code hard to maintain.
"The failure to encapsulate and abstract dependencies makes this code hard to maintain."

If you ever change your HTTP server, main has to change too. To add
middleware, you modify main. Major version changes in axum could force you to
change main.
We have the same issue with the database at 2, where we shackle our main
function to one particular, third-party implementation of an Sqlite client.
Next, we make things so much worse by flowing this concrete representation
– an imported struct entirely outside our control – through the entire
application. See how we pass sqlite into axum as a field of AppState 3
to make it accessible to our HTTP handlers?
To change your database client – not even to change the kind of database, just the code that calls it – you'd have to rip out this hard dependency from every corner of your application.
This isn't a leaky abstraction, it's a broken dam.
Take a moment to recover, because I'm about to show you the create_author
handler, and it's a bloodbath.
rustsrc/lib/routes.rs
Stay with me! Suppress the urge to vomit. We'll get through this together and come out as better Rust devs.
Look, there's that hard dependency on sqlx 5, polluting the system on cue 🙄. And holy good god, our HTTP handler is orchestrating database transactions 7. An HTTP handler shouldn't even know what a database is, but this one knows SQL!
rustsrc/lib/routes.rs
And the horrifying consequence of this is that the handler also has to understand the specific error type of the database crate – and the database itself 8:
rustsrc/lib/routes.rs
Refactoring this kind of code is miserable, you get that. But here's the kicker – unit testing this kind of code is impossible.
"Unit testing this code is impossible."
You cannot call this handler without a real, concrete instance of an sqlx SQLite connection pool.
And don't come at me with "it's fine, we can still integration test it", because that's not enough. Look at how complex the error handling is. We've got inline request body validation 6, transaction management 7, and sqlx errors 8 in one function.
Integration tests are slow and expensive – they aren't suited to exhaustive coverage. And how are you going to test the scenario where the transaction fails to start? Will you make the real database fall over?
This architecture is game over for maintainability. Nightmare fuel.
Hard dependencies and hexagonal architecture: how to make the right call
Hard dependencies aren't irredeemably evil – you'll see several as we build our hexagonal answer to the Very Bad Application – but they are use-case-dependent.
Tokio is a hard dependency of most production Rust applications. This is by necessity. An async runtime is a dependency on a grand scale, practically part of the language itself. Your application can't function without it, and its purpose is so fundamental that you'd gain nothing from attempting to abstract it away.
In these situations, consider the few alternatives carefully, and accept that changing your mind later will mean a painful refactor. Most of all, look for evidence of widespread community adoption and support.
HTTP packages, database clients, message queues, etc. do not fall into this category. Teams opt to change these dependencies regularly, for reasons including:
- scaling pressures that require new technical solutions,
- deprecation of key libraries,
- security threats,
- someone more senior said so.
It's critical that we abstract these packages behind our own, clean interfaces, forcing conformity with our application. In the next part of this guide, you'll learn how to do exactly that.
Hexagonal architecture brings order to chaos and flexibility to fragile programs by making it easy to create modular applications where connections to the outside world always adhere to the most important API of all: your business domain.
🦀🦀🦀
Part II
Separation of concerns, the Rust way
Getting started with hexagonal architecture
Our transition to hexagonal architecture begins here. We'll move from a tightly coupled, untestable nightmare to a happy place where production doesn't fall over at 3am.
We're going to transform the Very Bad Application gradually, zooming out a little at a time until you see the whole hexagon. Then I'll answer "why hexagons?". Promise.
I've omitted details like module names and folder structure for simplicity. Don't worry, though. Before this guide is over, you'll have a complete application template you can reuse across all your projects.
The repository pattern in Rust
The worst part of the Very Bad Application is undoubtedly having an HTTP handler making direct queries to an SQL database. This is a plus-sized violation of the Single Responsibility Principle.
Code that understands the HTTP request-response cycle shouldn't also understand SQL. Code that needs a database doesn't need to know how that database is implemented. These could not be more different concerns.
Hard-coding your handler to manage SQL transactions will come back to bite you if you switch to Mongo. That Mongo connection will need ripping out if you move to event streaming, to querying a CQRS service, or to making an intern do it by hand.
All of these are valid data stores. If you overcommit by hard-wiring any one of them into your system, you guarantee future pain when you can least afford it – when you need to scale.
"Hard-wiring a database into your system guarantees pain when you need to scale."
Repository is the general term for "some store of data". Our first step is to
move the create_author handler away from SQL and towards the abstract concept
of a repository.
A handler that says "give me any store of data" is much better than a handler that says "give me this specific store of data, because it's the only one I know how to use".
Your mind has undoubtedly turned to traits as Rust's way of defining behaviour
as opposed to structure. How very astute of you. Let's define an
AuthorRepository trait:
rust
An AuthorRepository is some store of author data with (currently) one method:
create_author.
create_author takes a reference to the data required to create an author 9,
and returns a Result containing either a saved Author, or a specific error
type describing everything that might go wrong while creating an author 10.
Right now, that's just the existence of duplicate authors, but we'll come back
to error handling.
AuthorRepository is what's known as a domain trait. You might also have heard
the term "port" before – a point of entry to your business logic. A concrete
implementation of a port (say, an SQLite AuthorRepository) is called an
adapter. Starting to sound familiar?
For any code that requires access to a store of author data, this port is the source of truth for how every implementation behaves. Callers no longer have to think about SQL or message queues, they just invoke this API, and the underlying adapter does all the hard work.
Domain models
CreateAuthorRequest, Author and CreateAuthorError are all examples of
domain models.
Domain models are the canonical representations of data accepted by your business logic. Nothing else will do. Let's see some definitions:
rust
Now, these aren't very exciting models (they'll get more exciting when we talk about identifying the correct domain boundaries and the special concern of authentication in Part III). But they demonstrate how the domain defines what data flowing through the system must look like.
If you don't construct a valid CreateAuthorRequest from the raw parts you've
received over the wire (or from that intern), you can't call
AuthorRepository::create_author. Sorry, jog on. 🤷
"Validations should be defined by the domain, not request handlers."
This pattern of newtyping should be familiar if you've read The Ultimate Guide to Rust Newtypes. If you haven't, I'll wait for you here.
Four special properties arise from this:
- Your business domain becomes the single source of truth for what it means to be an author, user, bank transaction or stock trade.
- The flow of dependencies in your application points in only one direction: towards your domain.
- Data structures within your domain are guaranteed to be in a valid state.
- You don't allow third-party implementation details, like SQL transactions or RPC messages to flow through unrelated code.
And this has immediate practical benefits:
- Easier navigation of the codebase for veterans and new joiners.
- It's trivial to implement new data stores or input sources – you just implement the corresponding domain trait.
- Refactoring is dramatically simplified thanks to the absence of hard-coded implementation details. If an implementation of a domain trait changes, nothing about the domain code or anything downstream from it needs to change.
- Testability skyrockets, because any domain trait, like
AuthorRepositorycan be mocked. We'll see this in action shortly.
Why do we distinguish CreateAuthorRequest 12 from Author 11? Surely we
could represent both saved and unsaved Authors as
rust
Right now, with this exact application, this would be fine. It might be annoying
to check whether id is Some or None to distinguish whether Author is
saved or unsaved, but it would work.
However, we'd be mistaken in assuming that the data required to create an
Author and the representation of an existing Author will never diverge. This
is not at all true of real applications.
I've done a lot of work in onboarding and ID verification for fintechs. The data required to fully represent a customer is extensive. It can take many weeks to collect it and make an account fully operational.
This is pretty poor as a customer experience, and abandonment would be high if you took an all-or-nothing approach to account creation.
Instead, an initial outline of a customer's details is usually enough to create a basic profile. You get the customer interacting with the platform as soon as possible, and stagger the collection of the remaining data, fleshing out the model over time.
In this scenario, you don't want to represent some CreateCustomerRequest and
Customer in the same way. Customer may contain dozens of optional fields and
relations that aren't required to create a record in the database. It would be
brittle and inefficient to pass such a needlessly large struct when creating a
customer.
What happens when the domain representation of a customer changes, but the data required to create one remains the same? You'd be forced to change your request handling code too. Or, you'd be forced to do what you should have done from the start – decouple these models.
Hexagonal architecture is about building for change. Although these models may look like duplicative boilerplate to begin with, don't be fooled. Your application will change. Your API will diverge from your domain representation.
"Hexagonal architecture is about building for change."
By modeling persistent entities separately from requests to create them, you encode an incredible capacity to scale.
Error types and hexagonal architecture
Let's zoom in on CreateAuthorError 13. It reveals some important properties
of domain models and traits.
CreateAuthorError doesn't define failure cases such as an input name being
invalid. This is the responsibility of the CreateAuthorRequest constructor
(which in this case delegates to the AuthorName constructor). Here's more
on using newtype constructors as the source of
truth if
you're unclear on this point.
CreateAuthorError defines failures that arise from coordinating the action of
adapters. There are two categories: violations of business rules, like
attempting to create a duplicate author, and unexpected errors that the domain
doesn't know how to handle.
Much as our domain would like to pretend the real world doesn't exist, many things can go wrong when calling a database. We could fail to start a transaction, or fail to commit it. The database could literally catch fire in the course of a request.
The domain doesn't know anything about database implementations. It doesn't know about transactions. It doesn't know about the fire hazards posed by large datacenters and your pyromaniac intern. It's oblivious to retry strategies, cache layers and dead letter queues (we'll talk about these in Part V: Advanced Hexagonal Architecture in Rust).
But it needs some mechanism to propagate unexpected errors back up the call
chain. This is typically achieved with a catch-all variant, Unknown, which
wraps a general error type. anyhow::Error is particularly convenient for this,
since it includes a backtrace for any error it wraps.
As a result (no pun intended), CreateAuthorError is a complete description of
everything that can go wrong when creating an author.
"
CreateAuthorErroris a complete description of everything that can go wrong when creating an author."
This is incredible news for callers of domain traits – immensely powerful. Any code calling a port has a complete description of every error scenario it's expected to handle, and the compiler will make sure that it does.
But enough theorizing! Let's see this in practice.
Implementing AuthorRepository
Here, I move the code required to interact with an SQLite database out of the
Very Bad Application's create_author handler and into an implementation of
AuthorRepository.
We start by wrapping an sqlx connection pool in our own Sqlite type. Module
paths for sqlx types are fully qualified to avoid confusion:
rust
Wrapping types like sqlx::SqlitePool has the benefit of encapsulating a
third-party dependencies within code of our own design. Remember the Very Bad
Application's leaky main function 1? Wrapping external libraries and
exposing only the functionality your application needs is how we plug the leaks.
"Wrap external libraries and expose only the functionality your application requires."
Again, don't worry about module structure for now. Get comfortable with the type definitions, then we'll assemble the pieces.
This constructor does what you'd expect, with the possible exception of the
result it returns. This constructor isn't part of the AuthorRepository trait,
so we're not bound by its strict opinions on the types of allowable error.
anyhow is an excellent crate for
working with non-specific errors. anyhow::Result is equivalent to Result<T, anyhow::Error>, and anyhow::Error says we don't care which error occurred,
just that one did.
At the point where most applications are instantiating databases, the only
reasonable thing to do with an error is log it to stdout or some log
aggregation service. Sqlite::new simply wraps any sqlx error it encounters
with some extra context 15.
Now, the exciting stuff – the implementation of AuthorRepository:
rust
Look! Transaction management is now encapsulated within our Sqlite
implementation of AuthorRepository. The HTTP handler no longer has to know
about it.
create_author invokes the save_author method on Sqlite, which isn't
specified by the AuthorRepository trait, but gives Sqlite the freedom to set
up and pass around transactions as it requires.
This is the beauty of abstracting implementation details behind traits. The trait defines what needs to happen, and the implementation decides how. None of the how is visible to code calling a trait method.
Sqlite's implementation of AuthorRepository knows all about SQLite error
codes, and transforms any error corresponding to a duplicate author into the
domain's preferred representation 18.
Of course, Sqlite, not being part of the domain's Garden of Eden, may
encounter an error that the domain can't do much with 19.
This is a 500 Internal Server Error in the making, but repositories shouldn't
know about HTTP status codes. We need to pass it back up the chain in the form
of CreateAuthorError::Unknown, both to inform the end user that something fell
over, and to capture for debugging.
This is a situation that the program – or at least the request handler – can't
recover from. Couldn't we panic? The domain can't do anything useful here, so
why not skip the middleman and let the panic recovery middleware handle it?
Don't panic
Until very recently, I would have said yes – if the domain can't do any useful work with an error, panicking will save you from duplicating error handling logic between your request handler and your panic-catching middleware.
However, thanks to a comment from matta and a horrible realization I had in the shower, I've reversed my position.
"Don't panic in response to unexpected errors."
Whether or not you consider the database falling over a recoverable error, there are two incontrovertible reasons not to panic:
- Panicking poisons held mutexes. If your application state is protected by
an
Arc<Mutex<T>>, panicking while you hold the guard will mean no other thread will ever be able to acquire it again. Your program is dead, and no amount of panic recovery middleware will bring it back. - Other Rust devs won't expect you to panic. Most likely, you won't be the person woken at 3am to debug your code. Strive to make it as unsurprising as possible. Follow established error handling conventions diligently. Return errors, don't panic.
What about retry handling? Good question. We'll cover that in Part V: Advanced Hexagonal Architecture in Rust.
Everything but the kitchen async
Have you spotted it? The mismatch between our repository implementation and the trait definition.
Ok, you caught me. I simplified the definition of AuthorRepository. There's
actually more to it, because of course we want database calls to be async.
Writing to a file or calling a database server is precisely the kind of slow, blocking IO that we don't want to stall on.
We need to make AuthorRepository an async trait. Unfortunately, it's not quite
as simple as writing
rust
Rust understands this, and it will compile, but probably won't do what you expect.
Although writing async fn will cause your method's return value to be sugared
into Future<Output = Result<Author, CreateAuthorError>>, it won't get an
automatic Send bound.
As a result, your future can't be sent between threads. For web applications, this is useless.
Let's spell things out for the compiler!
rust
Since our Author and CreateAuthorError are both Send, a Future that
wraps them can be too 20.
But what good is a repository if its methods return thread-safe Futures, but
the repo itself is bound to a single thread? Let's ensure AuthorRepository is
Send too.
rust
Ugh, we're not done. Remember about 4,000 words ago when we wrapped our
application state in an Arc to inject into an HTTP handler? Well, trust me, we
did.
Arc requires its contents to be both Send and Sync to be either Send
or Sync itself! Here's a good
discussion
on the topic if you'd like to know more.
rust
Your instinct might now be to implement AuthorRepository for &Sqlite instead
of Sqlite, since &T is immutable and therefore Send + Sync. However,
sqlx's connection pools are themselves Send + Sync, meaning Sqlite is too.
Are we done yet?
🙃
Naturally, if we're shuffling a repo between threads, Rust wants to be sure it
won't be dropped unexpectedly. Let's reassure the compiler that every
AuthorRepository will live for the whole program:
rust
Finally, our web server, axum, requires injected data to be Clone, giving our
final trait definition:
rust
From the Very Bad Application to the merely Bad Application
It's time to start putting these pieces together. Let's reassemble our
create_author HTTP handler to take advantage of the AuthorRepository
abstraction.
First, the definition of AppState, which is the struct that contains the
resources that should be available to every HTTP handler. This pattern should be
familiar to users of both axum and Actix
Web.
rust
AppState is now generic over AuthorRepository. That is, AppState provides
HTTP handlers with access to "some store of author data", giving them the
ability to create authors without knowledge of the implementation.
We wrap whatever instance of AuthorRepository we receive in an Arc, because
axum is going to share it between as many async tasks as there are requests to
our application.
This isn't our final destination – eventually our HTTP handler won't even know it has to save something (ah, sweet oblivion).
We're not quite there yet, but this is a vast improvement. Check out the handler!
rust
Oh my.
Isn't it beautiful?
Doesn't your nervous system feel calmer to behold it?
Go on, take some deep breaths. Enjoy the moment. Here's the crime scene we started from if you need a reminder.
Ok, the walkthrough. create_author has access to an AuthorRepository 22,
which it makes good use of. But first, it converts the raw
CreateAuthorHttpRequestBody it received from the client into the holy domain
representation 23. Here's how:
rust
Nothing fancy! Boilerplatey, you might think. This is by design. We have preemptively decoupled the HTTP API our application exposes to the world from the internal domain representation.
As you scale, you will thank this so-called boilerplate. You will name your firstborn child for it.
These two things can now change independently. Changing the domain doesn't
necessarily force a new web API version. Changing the HTTP request structure
does not require any change to the domain. Only the mapping in
CreateAuthorHttpRequestBody::into_domain and its corresponding unit tests get
updated.
This is a very special property. Changes to transport concerns or business logic no longer spread through your program like wildfire. Abstraction has been achieved.
Thanks to the pains we took to define all the errors an AuthorRepository is
allowed to return, constructing an HTTP response is dreamy. In the error case,
we map seamlessly to a serializable ApiError using ApiError::from 24:
rust
If the author was found to be a duplicate, it means the client's request was
correctly structured, but that the contents were unprocessable. Hence, we're
aiming to respond 422 Unprocessable Entity 27.
Important detail alert! Do you see how we're manually building an error message
at 28, even though CreateAuthorError::to_string could have produced this
error for us?
This is another instance of aggressive decoupling of our transport concern (JSON over HTTP) from the domain. Returning full-fat, unpasteurised domain errors to users is an easy way to leak private details of your application. It also results in unexpected changes to HTTP responses when domain implementation details change!
"Always separate your public errors from their domain representations."
If we get an error the domain didn't expect – CreateAuthorError::Unknown here
– that maps straight to InternalServerError 26.
The finer points of how you log the underlying cause will vary according to your needs. Crucially, however, the error itself is not exposed to the end user.
Finally, our success case 25. We take a reference to the returned Author
and transform it into its public API counterpart. It gets sent on its way with
status 201 Created.
rust
Chef's kiss. 🧑🍳
Testing HTTP handlers with injected repositories
Oh, it gets better.
Previously, our handler code was impossible to unit test, because we needed a real database instance to call them. Trying to exercise every failure mode of a database call with a real database is pure pain.
Those days are over. By injecting any type that implements AuthorRepository,
we open our HTTP handlers to unit testing with mock repositories.
rust
MockAuthorRepository is defined to hold the Result it should return in
response AuthorRepository::create_author calls 29 30.
The rather nasty type signature at 29 is due to the fact that
AuthorRepository has a Clone bound, which means MockAuthorRespository must
be Clone.
Unfortunately for us, CreateAuthorError isn't Clone, because
its Unknown variant
contains anyhow::Error. anyhow::Error isn't Clone since it's designed to
wrap unknown errors, which may not be Clone themselves. std::io::Error is
one common non-Clone error.
Rather than passing MockAuthorRepository a convenient Result<Author, CreateAuthorError>, we need to give it something cloneable – Arc. But, as
discussed, Arc's contents need to be Send + Sync for Arc to be Send + Sync, so we're forced to wrap the Result in a Mutex. (I'm using
a tokio::sync::Mutex here, hence the await, but std::sync::Mutex also
works with minor changes to the supporting code).
The mock implementation of create_author then deals with swapping a dummy
value with the real result in order to return it to the test caller.
Here's the test for the case where the repository call succeeds. I leave the error case to your powerful imagination, but if you crave more Rust testing pearls, I'll have a comprehensive guide to unit testing for you soon!
rust
At 31, we construct a MockAuthorRepository with an arbitrary success
Result. We expect that a Result::Ok(Author) from the repo should produce a
Result::Ok(ApiSuccess<CreateAuthorResponseData>) from the handler 32.
This situation is simple to set up – we just call the create_author handler
with a State object constructed from the MockAuthorRepository in place of a
real one 33. The assertions are self-explanatory.
I know, I know – you're itching to see what main looks like with these
improvements, but we're about to take a much bigger and more important leap in
our understanding of hexagonal architecture.
In Part III, coming next, I'll introduce you to the beating heart of an
application domain: the Service.
We'll ratchet up the complexity of our example application to understand how to set domain boundaries. We'll confront the tricky problem of master records through the lens of authentication, and explore the interface between hexagonal applications and distributed systems.
And yes, we'll finally answer, "why hexagons?".
🦀🦀🦀
Part III
Service, the heart of hexagonal architecture
Introducing the Service trait
The Repository trait does a great job at getting datastore implementation
details out of code that handles incoming requests.
If our application really was as simple as the one I've described so far, this would be good enough.
But most real applications aren't this simple, and their domain logic involves
more than writing to a database and responding 201.
For example, each time a new author is successfully created, we may want to dispatch an event for other parts of our system to consume asynchronously.
Perhaps we want to track metrics related to author creation in a time series database like Prometheus? Or send a welcome email?
This sequence of conditional steps is domain logic. We've already seen that domain logic doesn't belong in adapters. Otherwise, when you swap out the adapter, you have to rewrite domain code that has nothing to do with the adapter implementation.
So, domain logic can't go in our HTTP handler, and it can't go in our
AuthorRepository. Where does it live?
A Service.
A Service refers to both a trait that declares the methods of your business
API, and an implementation that's provided by the domain to your inbound
adapters.
It encapsulates calls to databases, sending of notifications and collection of metrics from your handlers behind a clean, mockable interface.
Currently, our axum application state looks like this:
rust
Let's spice up our application with some more domain traits:
rust
Together with AuthorRepository, these ports illustrate the kinds of
dependencies you might expect of a real production app.
AuthorMetrics 34 describes an aggregator of author-related metrics, such as
a time-series database. AuthorNotifier 35 triggers notifications to
authors.
Rather than stuffing these domain dependencies into AppState directly, we're
aiming for this:
rust
How do we get there? Let's start with the Service trait definition:
rust
Much like AuthorRepository, the Service trait has an async method,
create_author, that takes a CreateAuthorRequest by reference and returns a
Future that outputs either an Author, if creation was successful, or a
CreateAuthorError if not.
Although the signatures of AuthorService and AuthorRepository look similar,
this is a byproduct of a simple domain. They aren't required to match, and by
separating our concerns with traits in this way, we allow them to diverge in
future.
Now, the implementation of AuthorService:
rust
The Service struct encapsulates the dependencies required to execute our
business logic 36.
The implementation of AuthorService::create_author 37 illustrates why we
don't want to embed these calls directly in handler code, which has enough work
to do just managing the request-response cycle.
First, we call the AuthorRepository to persist the new author, then we branch.
On a failed repository call, we call AuthorMetrics to track the failure. On
success, we submit success metrics, then trigger notifications. In both cases,
we propagate the repository Result to the caller.
I defined the AuthorMetrics and AuthorNotifier methods as infallible, since
metric aggregation and notification dispatch typically takes place concurrently,
with separate error handling paths.
Not always, though. Imagine if the metrics and notifier calls also returned errors. Suddenly, our test scenarios include:
- Calls to all three dependencies succeed.
- The repo call fails, and the metrics call fails too.
- The repo call fails, and the metrics call succeeds.
- The repo call succeeds, but the metrics fall over.
- The repo and metrics calls succeed, but the notifier returns an error.
Now picture every permutation of these cases with all of the Results produced
when receiving, parsing and responding to HTTP requests 🤯.
This is what happens if you stick domain logic in your handlers. Without a
Service abstraction, you have to integration test this hell.
Nope. No. Not today, thank you.
"The
Servicetrait keeps your unit test surface area sane."
To test handlers that call a Service, you just mock the service, returning
whatever success or error variant you need to check the handler's output.
To test a Service, you mock each of its dependencies, returning the successes
and errors required to exercise all of the paths described above.
Finally, you integration test the whole system, focusing on your happy paths and the most important error scenarios.
Paradise 🌅.
Now you know how to wrap your domain's dependencies in a Service, and you're
happy that it's the service that gets injected into our handlers in AppState,
let's check back in on main.
main is for bootstrapping
The only responsibilities of your main function are to bring your application
online and clean up once it's done.
Some developers delegate bootstrapping to a setup function that does the hard
work and passes the result back to main, which just decides how to exit. This
works too, and the differences don't matter for this discussion.
main must construct the Services required by the application, inject them
into our handlers, and set the whole program in motion:
rust
To do this, main needs to know which adapters to slot into the domain's ports
38. This example uses an SQLite AuthorRepository, Prometheus
AuthorMetrics and an email-based AuthorNotifier.
It combines these implementations of the domain traits into an AuthorService
39 using the author domain's Service constructor.
Finishing up, it injects the AuthorService into an HTTP server and runs it
40.
Even though main knows which adapters we want to use, we still aim to not leak
implementation details of third-party crates. Here are the use statements for
this main.rs file:
rust
This is all proprietary to our application. Even though we're using an axum HTTP
server, main doesn't know about axum.
Instead, we've created our own HttpServer wrapper around axum that exposes
only the functionality the rest of the application needs.
Configuration of routes, ports, timeouts, etc. lives in a predictable place
isolated from unrelated code. If axum were to make changes to its API, we'd need
to update our HttpServer internals, but they'd be invisible to main.
There's another motivating factor behind this: main is pretty resistant to
testing. It composes unmockable dependencies and handles errors by logging to
stdout and exiting. The less code we put here, the smaller this testing dead
zone.
"The less code you put in
main, the smaller your testing dead zone."
Setup and configuration for integration tests is often subtly different from
main, too. Imagine having to configure all the routes and middleware for an
axum server separately for main and tests. What a chore!
By defining our own HttpServer type, both main and tests can easily spin up
our app's server with the config they require. No duplication.
Why hexagons?
Ok, it's time. It's actually happening.
I've shown you the key, practical components of hexagonal architecture: services, ports, adapters, and the encapsulation of third-party dependencies.
Now some theory – why hexagons?
Well, I hate to break it to you, but hexagons aren't special. There's no six-sided significance to hexagonal architecture. The truth is, any polygon will do.
"Any polygon will do."
Hexagonal architecture was originally proposed by Alistair Cockburn, who chose hexagons to represent the way adapters surround the business domain at the core of the application. The symmetry of hexagons also reflects the duality of inbound and outbound adapters.
I've been holding off on a classic hexagonal architecture diagram until I showed you how the ports and adapters compose. Here you go:
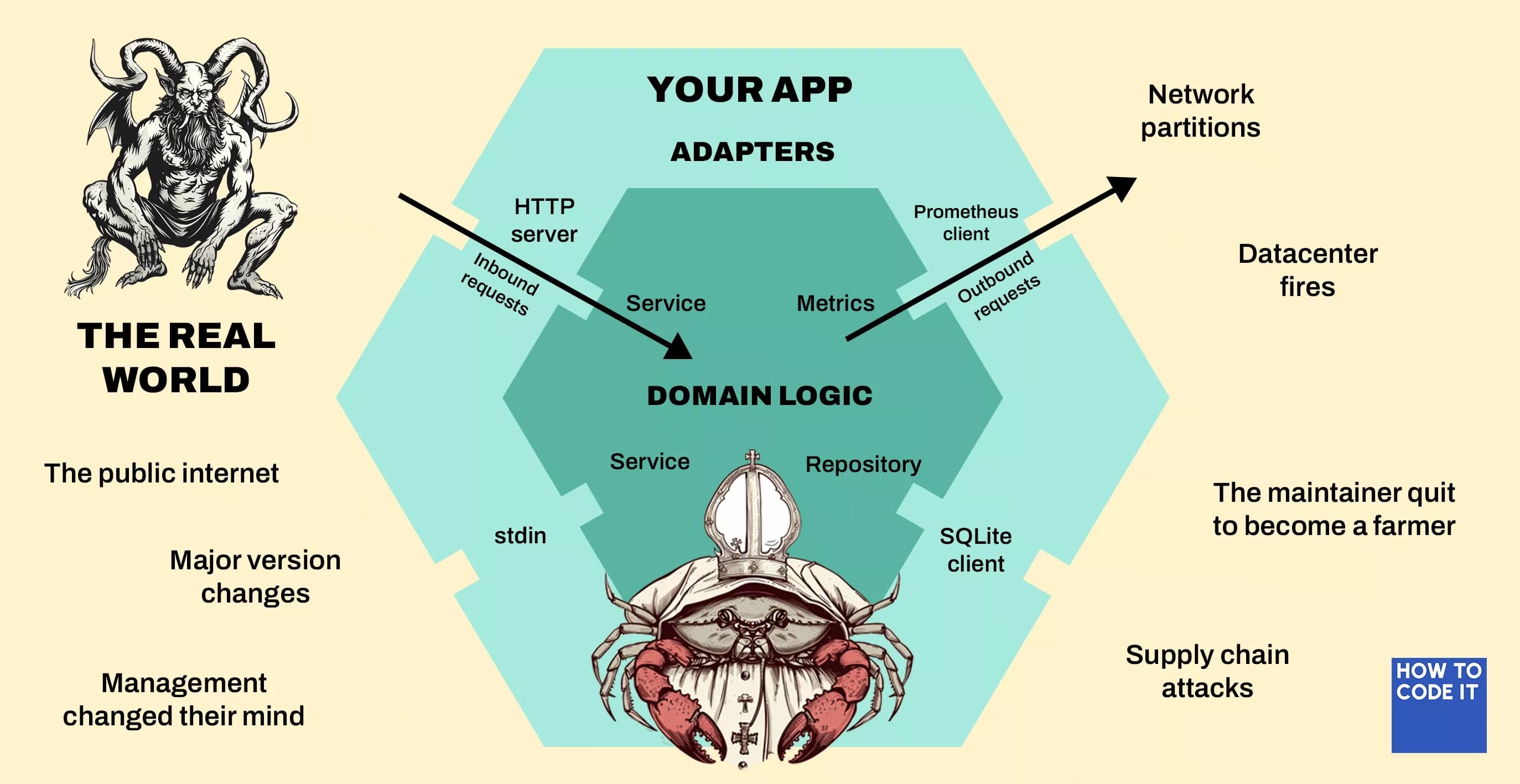
The outside world is a scary, ever-changing place. Anything can go wrong at any time.
Your domain logic, on the other hand, is a calm and tranquil glade. It changes if, and only if, the requirements of your business change.
The adapters are the bouncers enforcing the domain's dress code on anything from the outside that wants to get in.
How to choose the right domain boundaries
What belongs in a domain? What models and ports should it include? How many domains should a single application have?
These are the questions many people struggle with when adopting hexagonal architecture, or domain-driven design more generally.
I've got good news and bad news 💁.
The bad news is that I can't answer these questions for you, because they depend heavily on variables like your scale, your overall system architecture and your requirements around synchronicity.
The good news is, I have two powerful rules of thumb to help you make the right decision, and we'll go through some examples together.
Firstly, a domain represents some tangible arm of your business.
"A domain represents some tangible arm of your business."
I've been discussing an "author domain", because a using single-entity domain makes it easier to teach the concepts of hexagonal architecture.
For a small blogging app, however, it's likely that a single "blog domain" would be the correct boundary to draw, since there is only one business concern – running a blog.
For a site like Medium, there would be multiple domains: blogging, user
identity, billing, customer support, and so on. These are related but distinct
business functions, that communicate using each other's Service APIs.
If this is starting to sound like microservices to you, you're not imagining things. We'll talk about the relationship between hexagonal architecture and microservices in Part IV.
Secondly, a domain should include all entities that must change together as part of a single, atomic operation.
"A domain should include all entities that must change together as part of a single, atomic operation."
Consider our blogging app. The author domain manages the lifecycle of an
Author. But what about blog posts?
If an Author is deleted, do we require that all of their posts are deleted
atomically, or is it acceptable for their posts to be accessible for a short
time after the deletion of the author?
In the first case, authors and posts must be part of the same domain, since the deletion of an author must be atomic with the deletion of their blog posts.
In the second case, authors and posts could theoretically be represented as separate domains, which communicate to coordinate deletion events.
This communication could be synchronous (the author domain calls and awaits
PostService::delete_by_author_id ) or asynchronous (the author domain pushes
some AuthorDeletionEvent onto a message queue, for the post domain to process
later).
Neither of these cases are atomic. Business logic, being unaware of repository implementation details, has no concept of transactions in the SQL sense.
If you find that you're leaking transactions into your business logic to perform cross-domain operations atomically, your domain boundaries are wrong. Cross-domain operations are never atomic. These entities should be part of the same domain.
"If you leak transactions into your business logic to perform cross-domain operations atomically, your domain boundaries are wrong."
Start with large domains
According to the first rule of thumb, we wouldn't actually want to separate authors and posts into different domains. They're part of the same business function, and cross-domain communication complicates your application. It has to be worth the cost.
We're happy to pay this cost when different parts of our business rely on each other, but need to change often and independently. We don't want these domains to be tightly coupled.
Identifying these related but independent components is an ongoing, iterative process based on the friction you experience as your application grows.
This is why starting with a single, large domain is preferable to designing many small ones upfront.
If you jump the gun and build a fragmented system before you have first-hand experience of the points of friction in both the system and the business, you pay a huge penalty.
You must write and maintain the glue code for inter-domain communication before you know if it's needed. You sacrifice atomicity which you might later find you need. You will have to undo this work and merge domains when your first guess at domain boundaries is inevitably wrong.
A fat domain makes no assumptions about how different business functions will evolve over time. It can be decomposed as the need arises, and maintains all the benefits of easy atomicity until that time comes.
"Start with a single, large domain."
Authentication and authorization with hexagonal architecture
I was deliberate in choosing Authors rather than Users for our example
application. If you're used to working on smaller, monolithic apps, it's not
obvious where entities like Users belong in hexagonal architecture.
If you're comfortable in a microservices context, you'll have an easier time.
The primary entity for authentication and authorization will "own" many other
entities. A User for a social network will own one or more Profiles,
Settings, Subscriptions, AccountStatuses, and so on. All of these, and all
the data that they own in turn, are traceable back to the User.
If we follow our rule of thumb – that entities that change together atomically
belong in the same domain – the presence of master records causes everything
to belong in the same domain. If you delete a User, and require synchronous
deletion of related entities, everything must be deleted in the same, atomic
operation.
Isn't this the same as having no domain boundaries at all?
For a small to medium application, where you roll your own auth and aren't expecting massive growth, this is fine. Overly granular domains will cause you more problems than they solve.
However, for larger applications and apps that use third-party auth providers like Auth0, a single domain is unworkable.
The User entity and associated auth code should live in its own domain, with
entities in other domains retaining a unique reference to the owner. Then,
depending on your level of scale, deletions can happen in two ways:
- Synchronously, with the auth domain calling each of the other domains'
Service::delete_by_user_idmethods. - Asynchronously, where the auth domain publishes a deletion event for other domains to process on their own time.
Neither of these scenarios is atomic.
Regardless of what architecture you use, atomic deletion of a User and all
their dependent records get taken off the table once you reach a certain scale.
Hexagonal architecture just makes this explicit.
To use an extreme example, deletion of a Facebook account, including everything it has ever posted, takes up to 90 days (including a 30-day grace period). Even then, copies may remain in backups.
In addition to the vast volume of data to be processed, there will be a huge amount of internal and regulatory process to follow in the course of this deletion. This can't be modeled as an atomic operation.
"At a certain scale,
Userdeletion can't be modeled atomically."
A Rust project template for hexagonal architecture
Until now, I've avoided discussing module paths and file structures because I didn't want to distract from the core concepts of domains, ports and adapters.
Now you have the full picture, I'll let you explore this example repository at your leisure and take inspiration from its folder structure.
Branch 3-simple-service contains the code we've discussed in part three of
this guide, and provides a basic but representative example of a hexagonal app.
Dividing src/lib into domain (for business logic) inbound and outbound
(for adapters) has worked well at scale for several teams I've been part of.
It's not sacred though. How you name these modules and the level of granularity
you choose should suit your own needs.
All I ask is that, whatever convention you adopt, you document it for both new and existing team members to refer to.
Document your decisions, I beg you.
Make an informed decision
In Part IV, we'll be discussing the trade-offs of using hexagonal architecture compared with other common architectures, and see how it simplifies the jump to microservices when the time is right.
🦀🦀🦀
Part IV
Trade-offs of hexagonal architecture in Rust
Put down the Kool-Aid
By this point in the guide, you likely fall into one of two camps.
In the first camp, my converts have sold their possessions and donated the proceeds to the six-sided church. They gather round the fire to sing songs in praise of Hexagonal Architecture, hallowed be its name.
Across the creek, the second camp hunger for blood. Triggered by the structure, formality and upfront complexity of hexagonal architecture, they prepare to sacrifice the false idol on the bonfire of software engineering trends. They're incensed by the suggestion that hexagonal architecture is superior to others.
Each camp checks its map of the software development landscape, seeking the most effective path to destroy the other. To their surprise, however, the map shows nothing but a great swamp, without end or beginning. This is "The Middle Ground".
Strengths and weaknesses of hexagonal architecture
Hexagonal architecture is a power tool. It's the hydraulic press of software architectures, and whether it's the optimal architecture for you depends on whether you want to crush a car or a Coke can.
Parts I to III showed off the strengths of hexagonal architecture:
- It's highly decoupled, making it a pleasure to evolve and scale.
- It greatly increases your unit test surface for rigorous testing of code with complex failure modes.
- There's a single source of truth for the logic of each business domain, with a correspondingly simple dependency graph.
- There's a home for everything. A predictable project structure keeps your code organized and your team happy.
Nothing comes for free, though. What are the costs?
Compared to the Very Bad Application 1, our hexagonal app takes a lot more code to achieve the same result. Instead of a raw, axum HTTP handler that simply takes the request body and shoves it straight into an SQLite database, we have multiple layers of abstraction:
- axum becomes an implementation detail, concealed by our own HTTP package.
- The request body must be converted to a domain representation before we can work with it.
- Business logic is encapsulated by the
Servicetrait and injected into the handler. - SQLite is an implementation detail hidden behind a repository trait implementation.
- Anything we pull out of the database has to be converted to a domain representation before it can be used.
This isn't boilerplate. It's not useless filler. All this extra code is required to achieve the benefits listed above. But clearly there's a threshold below which you'll spend more time writing abstractions and transformations than you'll save through easy scaling and fewer production incidents.
Translations from transport data types to domain data types aren't free, either. For many apps, the cost is negligible – a tiny fraction of the compute required by the business logic. But for some apps this matters. For embedded software, every byte of memory might count. High-performance systems, such as high-frequency trading software, sacrifice readability for speed. Hexagonal architecture would be a poor fit.
Let's not forget the barrier to entry. Here we are, thousands of words deep into a hexagonal architecture tutorial. Getting it right requires time and space for active learning. Sustaining a hexagonal codebase requires a clear technical vision and a well-trained team. Everyone must understand the rationale and implementation of the architecture.
Most tech companies fail to invest in their people this way. The training and development available to professional software engineers is dire, and initiatives like adopting hexagonal architecture are led by evangelists learning on their own time. Sadly, they're doomed to fail, because building this way requires a culture that gets everyone on the same page.
"Adopting hexagonal architecture isn't just a technical investment, it's a cultural one."
Assuming I haven't scared you off, let's go through some examples to help you decide if hexagonal architecture is right for you.
Is hexagonal architecture right for you?
Solo developers and personal projects
If you're in the blessed position of being able to keep your entire codebase in your head – and you don't plan to share it – hexagonal architecture will slow you down.
As a solo dev, you'll have a clear idea of how likely you are to swap out your database, introduce async messaging or migrate to RPC from REST (probably never). And what good will increasing your test surface do if you can just eyeball your app to see that it's working?
In this scenario, abstractions like services and repositories make your code more fragile, not less. It's more code to mentally account for, with no practical upside.
However, I do recommend small, personal projects as playgrounds to learn and experiment with hexagonal architecture. Building a complete application, even a trivial one, will develop your ability to think hexagonally.
"Use small, personal projects as playgrounds to learn and experiment with hexagonal architecture."
Legacy code is created by engineers learning new techniques on the job. Take the time to build your intuition in a low-stakes environment. Go deep on details like domain boundaries and error handling. Write better-than-production code at home, then bring your expertise to work.
Applications with little business logic
Does your program tick along happily on an eighth of a vCPU? Is it a lightweight CRUD app that just writes what it's given and reads what it's asked for? Is deserializing a kilobyte of JSON the most ambitious thing it's done this week?
Don't overcomplicate things. Apps that don't have any business logic don't need ports and adapters – there's nothing to encapsulate.
"Apps that don't have any business logic don't need ports and adapters."
If you're compelled to test your request handlers in isolation from your data store, you might still consider using the repository pattern. On the other hand, if your app is so basic that this would be more effort than comprehensively integration testing, int test instead.
Startups that want to scale hard
You're a one-man band or a small team. Your code just about fits in your head, and the business logic doesn't do anything crazy. But you've got dreams. You want to take this all the way, and you need a rocket to get you there.
Build hexagonally. If you can do this from day one, all the better. Don't find yourself cruising towards your series A with the engines on fire and half your dev team trying to put it out.
Hexagonal architecture gives you comprehensive test coverage from the start. It allows you to make the wrong choice of database and spring gracefully away from danger. It lets you support new customer needs without mangling what already works. It's not just an architecture of scale, it's an architecture for scaling.
"It's not just an architecture of scale, it's an architecture for scaling."
Hexagonal architecture also saves you from true folly – launching your product as microservices.
In "How to choose the right domain boundaries", we learned about the importance of starting with few, large business domains. Each domain encapsulates entities that change atomically.
We start with large domains because our instincts about where domain boundaries should be are often wrong. User behavior causes applications to evolve organically. As domains get smaller, you'll find yourself correcting the boundaries – and their dependent code – more often.
"Battle-testing your app reveals entities and relations you can't predict."
Now imagine you work for a stealth start-up building its MVP. Karl, the founder, calls you over to talk architecture. You're concerned by Karl's recent weight loss and accelerated balding. Did he always have that facial tic?
Your company doesn't have customers yet, but Karl claims to know what the correct domain boundaries are, having seen them in a dream. You think this unlikely, since he doesn't appear to have slept.
Karl is so confident in these boundaries that he orders you to place each domain in a separate microservice. In the face of your protests, he mutters something about "extreme scale" and "the valuation", and sacrifices a goat to the dark god of network partitions*.
This is what go-live looks like with microservices. All the pain of incorrect domain boundaries, now with network hops.
By starting with a coarse-grained hexagonal monolith, you can refine your domain boundaries in response to observed use patterns. If and when you reach the organizational scale where microservices are necessary, it's a relatively simple matter of extracting these battle-tested domains into their own microservices.
Remember – a hexagonal domain doesn't care where it gets its requests from. It could be a request from another domain running in the same process. It could be an RPC from an internal microservice, or a RESTful request from the outside world. It doesn't matter.
"Hexagonal architecture scales."
Big team, big monolith, big headache
Most teams reach for microservices when their monolith has become too large, overloaded and impenetrable to manage. They're resigned to PR conflict purgatory because everyone's code is interdependent and build times are charted by the passage of seasons.
If this is you, and you have the power to lead architectural change, please consider refactoring your chaotic evil monolith to a hexagonal monolith before making the leap to microservices.
"If you can't build a modular monolith, you're not qualified to run microservices."
The situation won't be improved by pulling out a group of features that look like they belong together, putting them somewhere else on the network, and calling it a microservice.
That initial decomposition is a guess at where the domain boundaries are. Code that once depended on the extracted service will now be making fallible network calls. You will find, inevitably, that some of these should have stayed in-process. You might find that more should have been cut away from the monolithic flank. Unfortunately, now that there are many theoretically – but not practically – independent microservices, it's unclear where this orphaned code should live.
Migration to a hexagonal monolith turns the difficulty down by taking out the networking element. Start by identifying just one business domain you'd like to extract from the monolith. Your first stab at decomposition shouldn't move this to a microservice, but to a clearly bounded domain within the existing monolith, called via ports and adapters.
"Migrate to clearly bounded domains within your existing monolith."
Observe how the the rest of the tangled, heretical codebase interfaces with your hexagonal sanctuary. Refine the boundaries until they stabilize. This is much easier without the network hop. When the API to your domain is reasonably stable, it's ready to become a microservice.
Of course, the reason microservices seem so appealing is because they solve organizational pressures (teams treading on each other's toes) and resource pressures (big boxes to run big apps). How does hexagonal decomposition address that if all the code still lives in the same app?
"Prioritize the code that causes the biggest organizational and resource pressures."
An old monolith may take years to decompose, but it's not an all-or-nothing process. Prioritize the code that causes the biggest organizational and resource pressures, grit your teeth for a couple of months to make it hexagonal – get the domain boundaries right – then pull those domains into microservices. You don't have to refactor the whole application before extracting stable domain APIs.
By rushing towards a distributed architecture, you'll turn a bad monolith into bad microservices. Legacy®: Networked Edition.
By guinea-pigging internal domains, you introduce the network complexity only after the business complexity is solved.
Greenfield projects in established companies
If you work for the kind of large, established business where success is more about saying yes to the right people than writing good code, you may be tempted to stop reading here and go back to speculating when your next stock options will vest. You have my full support.
However, if you find yourself in a position to influence the direction of a new codebase within a well-resourced, established organization, use hexagonal architecture to cultivate a serene glade within Mirkwood.
Here's why:
- The business logic must be at least moderately complex, or the business wouldn't bother assembling a team for it.
- Dependencies like databases, message queues, etc. will certainly change based on the whims and shifting preferences of higher-ranking managers.
- This project – assuming it isn't canned when the quarterly earnings fall short – may be maintained for years, by hundreds of people who aren't you. You owe them a sane project structure with proper test coverage.
Cultural inertia may be against you. The whole team needs to buy in to hexagonal architecture and understand how it hangs together. If they're as excited as you are to start fresh and do better, you might just pull it off.
High-performance applications
We all like our apps to go fast, but "fast" is a relative term.
No user will perceive a speed difference between web app that lets its HTTP request types flow through the whole codebase, and a hexagonal app that parses transport-layer models into domain representations. But these transformations do have a cost, and if you're working on the kind of project where these costs matter, you already know it's too steep.
If you rely heavily on zerocopy, if your application shares memory with your network card, if you ever find yourself wondering if rustc is outputting the optimal assembly... my apologies – you don't have the nanoseconds to spare for hexagonal architecture.
Adopting hexagonal architecture
If you've decided that hexagonal architecture meets your needs, the fifth and final section of this guide will leave you with a wealth of practical Rust recipes. Each one will address a specific problem you might encounter as you adopt hexagonal architecture. I'm so excited to hear what you build.
🦀🦀🦀
Part V
Advanced hexagonal architecture in Rust
Part five is coming next!
Exercises
Well done for making it to the end of this guide. Next, put your new knowledge into practice with these exercises!
Stuck? Ask your questions in the comments below, and the How To Code It community will help you out.
If you're hungry for more, stay up to day with the latest guides and exercises in the How To Code It newsletter.
One newsletter per week, max. Let's face it, I'm not that consistent. Unsubscribe whenever. Privacy policy here.
Pick a large codebase that you work on regularly. Take some time to study it and list its hard-coded dependencies.
These are the dependencies that, if they disappeared from the internet tomorrow, would force you to change many functionally unrelated parts of your application.
Try to identify the parts of your codebase that these dependencies don't belong in, but would be hard to remove from.
Are your HTTP handlers talking to databases? Are you configuring middleware in main? Have Kafka errors leaked into non-Kafka code? Do you have RPC data models anywhere outside of RPC modules?
For any application of significant size, none of this is a sign of good health. Start auditing what seems "leaky". We're going to fix it.
Define async find and findAll methods on AuthorRepository.
Consider the error scenarios your domain should handle and design return types to cover these cases.
Implement your extended AuthorRepository for a database of your choice, using
my Sqlite struct as reference.
How will you handle unexpected error scenarios? Will you panic or return a catch-all domain error variant? You should feel confident that you could defend your decision in a hypothetical code review.
